LLMの内部構造の理解 「The Super Weight in Large Language Models」

この記事は、AIの内部構造に興味がある人に向けたものとなっています。
現在、LLMの内部はほとんどブラックボックス化しており、まだ理解が進んでいないのが現状です。内部の理解が進むことでLLMがより発展していき、さらなる成長が見込めます。そこで今回、LLMの内部構造の理解を進める研究をみていきます。
具体的に、Apple社が発表した論文「The Super Weight in Large Language Models」で興味深かった内容についてまとめていきます。
最近の研究
最近の研究では、LLMのたった一つのパラメータを削除するだけでテキスト生成能力が失われ、ゼロショット能力が推論レベルにまで低下することが分かっています。
研究の概要
本研究では、こうした重要なパラメータをスパーウェイトと名付け、モデルを1回だけ順伝搬させることでこれらを特定するデータ不要な手法を提案しています。また、スーパーウェイトは活性化関数の出力を極端に大きくする(スーパーアクティベーション)ことが分かりました。
スーパー重みの位置特定
スーパー重みは、層ごとの入力と出力におけるスパイクを検出することで特定することができます。この場合、通常の訓練データを必要とせず、単一の入力プロンプトのみを使用します。その結果、「Mistral-7B-Instruct-v0.1」や「Llama-2-7B-chat」などのインストラクションチューニング済みのモデルでは、スーパーウェイトが事前学習モデルと同じ座標に位置していることが分かりました。
出力トークンへの影響
スーパーウェイトが出力トークンに与える影響を調査しています。結果として、スーパーウェイトを削除すると、停止語(意味的に重要でない言葉 例 the, is, in…)の出力確率が増大することが分かりました。逆に、スーパーウェイトを増幅することでモデルの精度がある程度向上することが確認されました(以下の図参照)。
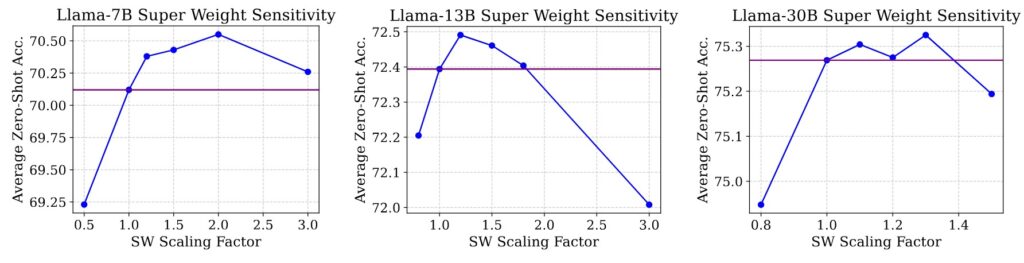
The Super Weight in Large Language Models, Fig6からの引用
まとめ
スーパーウェイトは精度を向上するために重要なパラメータであることが分かったがなぜスーパーウェイトが精度向上にこれだけ寄与しているのか?また、なぜスーパーウェイトが増幅することでモデルの精度が向上するのかは理解ができない。たまたま向上しているだけなんじゃないかな?